Why We Don't Believe MIT NANDA's Weird AI Study

The recently-gone-viral research study branded to MIT's NANDA organization titled "State of AI in Business 2025" has mysteriously gone viral, despite some obvious flaws in its data and conclusions.
Don't believe it. Not only is the report confusing, but it seems like a blatant case of propagandized clickbait, looking to draw people into headlines that have repeated its shaky "95% of Enterprise AI fails" headline.
That didn't stop lazy reporters and LinkedIn influencers from jumping all over the headline, despite the report's generic AI-infused style and incomprehensible leaps of logic (or illogic). To start with, it's not even easy to get hold of the report, which is hidden behind a cryptic form.
Obvious Bias and Agenda
Let's start with the publication and the potential agenda.
The report was published last week by the “NANDA Project at MIT.” NANDA stands for “Networked Agents and Decentralized AI.” It is a spinoff project from the MIT Media Lab designed to create new protocols and a new architecture for autonomous AI agents. The technology is supported by a number of powerful companies, including Google and Anthropic. Some of the authors work at some of these vendors. The MIT connection is the MIT Media Lab, but it's clear that this is not a traditional academic research paper, as it lacks thorough sourcing.
NANDA itself says it “builds on Anthropic's Model Context Protocol (MCP) and Google's Agent-to-Agent (A2A) to create comprehensive distributed agent intelligence infrastructure." The report is filled with references to these technologies, so there is obviously an agenda, and its connection to MIT is rather loose.
So, was this some kind of stealth guerrilla marketing project? I would say if that was the approach, it was a grand success, given that it spread everywhere despite obvious flaws in the data and conclusions. But after reading the report I can’t say I would feel safe reaching the same conclusions based on its messy data. So let’s dive in.
Cherry Picking for Headlines
Let's take a look at the clickbait headline, which by most measures is not even accurate. The research was published late last week and started spreading like wildfire over the weekend via the business press and LinkedIn. By Sunday my LinkedIn feed was 95% filled with “95% of AI fails” headlines.
Forbes: "95% of Enterprise AI Fails ..."
Fortune: "An MIT report that 95% of AI pilots fail spooked investors..."
Inc.: "MIT Reveals That 95 Percent of AI Pilots Fail"
This brings us to the first problem. Nowhere in the report does it present data to this effect. The 95% figure is presented in one sentence, but the authors offer no detail on where they came up with that number. Most of data and sample sizes present a different picture, but it leaves out basic information.
The report alludes to 52 interviews and hundreds of data points, but very little of the demographics of the pool or how the data was collected were disclosed. The few interviews that are quoted are done so anonymously.
Wharton Professor Questions Findings
But don't take it from me. Kevin Werbach, Wharton Professor and Chair of Legal Studies & Business Ethics, comes to the same conclusion.
In a LinkedIn post, Werbach dug into the report with a critical eye. His detailed takedown was buried under dozens of vapid LinkedIn reposts of the superficial press coverage.
This paragraph from Werbach about sums it up:
And then... there appears to be no further support for the 95% claim. I've read through the document multiple times, and I still can't understand where it comes from. There is a 5% number in Section 3.2, for "custom enterprise AI tools" being "successfully implemented." But that's much narrower. And successful deployment is defined as "causing a marked and sustained productivity and/or P&L impact." In other words, "unsuccessful" explicitly does not mean "zero returns."
Exactly. The categorizations of a lack of progress are missing data points and presented with incomprehensible charts.
Werbach concludes: "If MIT Project NANDA stands behind the claims, it should release the full supporting data. If not, it should retract the report."
Is 5% of 20% Actually 95% of Nothing?
As Werbach points out, looking through this report with any kind of methodical analysis, you'd be hard-pressed to come up with the conclusion of the 95% failure rate.
The closest the report comes to quantifying GenAI failures, which it does very poorly, comes in an "Exhibit" that describes "The steep drop from pilots to production for task-specific GenAI tools reveals the GenAI divide."
See below for the chart.

Source: "State of AI in Business," NANDA Project at MIT
First of all, the title doesn't necessarily reflect a "steep drop" or tell us how they reach that conclusion. On the face of it, 80% of companies investigated LLMs and 60% of those investigated task-specific GenAI (what does that even mean?). Of those, 40% successfully implemented general purpose LLMs out of pilot projects. That seems to indicate decent success.
Looking for where people come up with the 95% number requires diving into a smaller sample size—those that piloted "task-specific" GenAI. The chart doesn't explain the sample sizes, nor the relationship between the samples. I assume that the analysts (and reporters) might be saying that because only 5% of those implementing task-specific GenAI registered as successful, that means 95% failed. But even that doesn't work, because it's a subset of the larger data set. And we're not sure if they are referring to the 5% of all the people that investigated AI, or only those that piloted task-specific AI.
There's more: How did the "investigated" convert to "piloted"? Is the "successfully implemented" number part of the "investigated" sample, the pilot pool, or the whole sample? It's not explained, nor is the full data disclosed. If the report is concluding that 80% of people that don’t have task-specific AI pilots are failing at GenAI, that's an illogical leap. It’s like saying “95% of drivers failed at driving a car,” when 80% of those people don’t even have cars or have been taught how to drive.
But at this point, the data already lacks credibility, because it is poorly explained.
More Sloppy Data
That’s not the only place where the data is sloppy or confusing. For example, let’s try to understand something about the success rate in vertical industries. In the chart below, the x-axis is not even labeled.
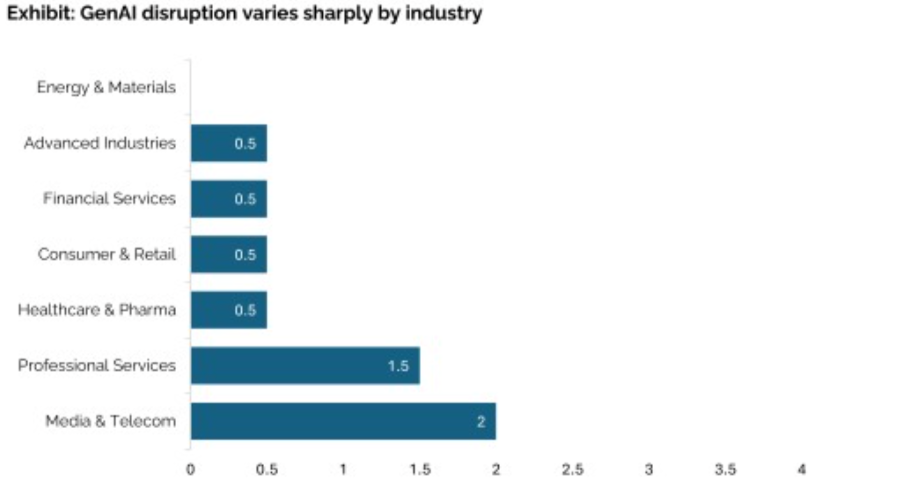
Source: "State of AI in Business," NANDA Project at MIT
What is the mysterious number at the bottom? The data appears to pertain to random vertical industries ranging from Energy & Materials to Financial Services that are labeled with numbers ranging from 0 to 4, but we are not told what those numbers are or how they are derived. With this unlabeled data, we are told that Energy & Materials ranks “0,” meaning the authors could find no gains in the entire energy and materials industry.
Because why?
But let's take a gut check. The fact that the authors concluded that there are zero returns in energy and materials and larger returns in media and telecom smells very funny. AI is clearly used to optimize energy consumption worldwide.
Why Not Look at the Real World?
The reason why we find this frustrating is that it doesn't match our own measure of reality. Futuriom's Cloud Tracker Pro service is building our own proprietary database of enterprise AI case studies. These are all verifiable and publicly sourced. Own our data, taken from real-world sources, shows a completely different picture.
We have found numerous cases of publicly documented success in enterprise AI. In fact, in our database of more than 130 enterprise case studies, the enterprises cited explicit gains, benefits, and direct ROI.

Specifically, in the energy sector vertical, companies cited wide-ranging benefits such as process optimization, risk and security management, data-driven insights, cost management, and energy optimization.
To be clear, our data will have a bias too. Because we are taking a careful look at success, rather than failure, our pool includes the most successful implementations of AI. But it's clear from our initial research that it's just not possible that 95% of companies are failing at AI if some of the largest companies in the world are demonstrating success.
Let's just give a few examples from our database:
- JPMorgan Chase cites reduced financial losses, improved operational efficiency, and increased customer satisfaction through its use of AI.
- Macy's has improved customer engagement with its credit card and loyalty programs as a result of its Rokt partnership.
- Massive Bio utilizes advanced algorithms (including NLP and Computer Vision) enhanced by GPT-4 and deep learning to automatically and accurately extract critical patient data from EHRs.
- Mastercard's AI-generated tool for speeding up customer service has resulted in measurable productivity for agents.
- Nestle's own internal version of ChatGPT (NesGPT) allowed employees across diverse functions (sales, innovation, marketing, legal) to quickly experiment with and integrate generative AI into their daily workflows. The company believes it significantly accelerates ideation from six months to six weeks.
- Novo Nordisk created its NovoScribe automated documentation tool, reducing resource needs by 80% and speeding up documentation time from weeks to minutes.
You can find some of this data here, but we have a lot more coming. What we have been finding are large numbers of targeted use cases in which enterprises are, in fact, generating returns on GenAI. This data shows a major disconnect with what the MIT NANDA study purports to find.
Futuriom Take: We aren't AI cheerleader purists—there are certainly many problematic areas of AI as well as investment patterns that warrant bubble fears—but the MIT NANDA report paints an irresponsible and unfounded picture of what's happening in Enterprise AI.











