PlanetScale Adds Fast Cloud Database Recovery

The world of cloud databases is arcane and mysterious, but PlanetScale, a company offering a serverless SQL database for hyperscale applications, aims to make it simpler.
In its latest announcement, the four-year-old startup describes a way for developers to immediately reverse any errors made during schema migrations.
Called PlanetScale Rewind, the technology lets developers instantly revert to the original schema in the event they make a mistake while modifying the PlanetScale database. Sort of like being able to rescue the right version of a spreadsheet you accidentally closed.
This may sound simple, but it reflects a complicated reality. Database technology is challenging at scale, and up to now, making a mistake in changing a cloud SQL database has often been a nightmare, leading to lost data and hours of downtime. And downtime isn’t an option for companies like YouTube, Slack, Square, GitHub, and Airbnb, all of which are PlanetScale customers.
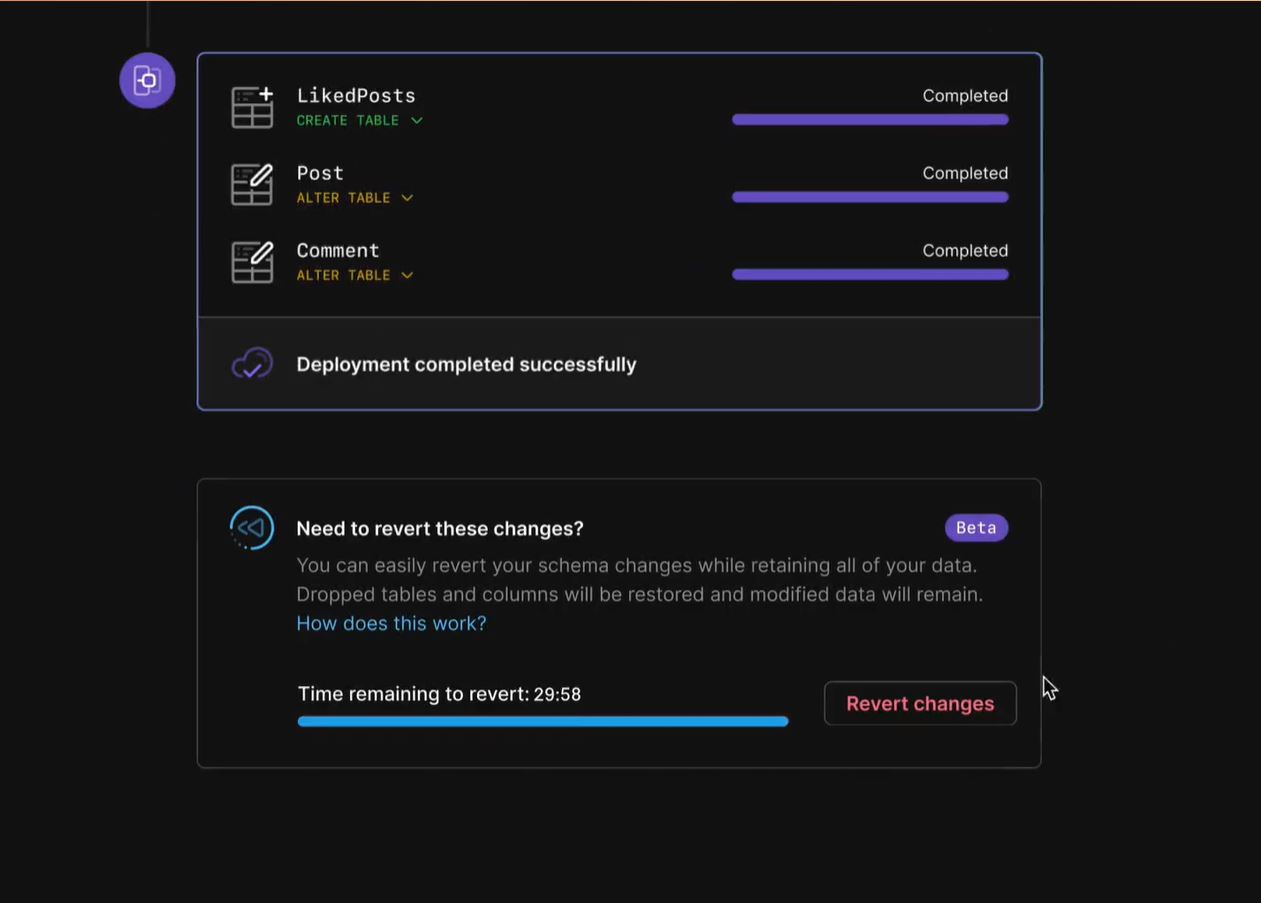
PlanetScale's Rewind. Source: PlanetScale.
PlanetScale’s founders include Sugu Sougoumarane, now CTO, who was instrumental in helping YouTube avoid crashes as its data grew to ginormous proportions. Sougoumarane's solution was a database orchestration system called Vitess. Another co-founder, Jiten Vaidya, now chief strategy officer at PlanetScale, also worked at YouTube and on similar projects at Dropbox and Google.
What's Behind PlanetScale's Scalability
Described as a “database clustering system for horizontal scaling of MySQL,” Vitess, along with MySQL, is the foundation of PlanetScale. Though work on Vitess began in 2010, since 2018 it has been managed as an open source project by the Cloud Native Computing Foundation. PlanetScale's commercial product extends Vitess’s capabilities with developer-friendly functions such as Rewind.
For PlanetScale, founded in 2018 and headquartered in Mountain View, Calif., the goals have been scalability, performance, and ease of development from the outset. Each PlanetScale database supports up to 250,000 connections and up to 20 petabytes of storage for hundreds of millions of queries per day. The speed and scale are suited to financial transaction processing, cloud gaming, media sites, and crypto mining. PlanetScale is available as multi-tenant SaaS and also as a managed service within a customer’s AWS account.
Not Your Geo-Dispersed DBMS
Notably, PlanetScale doesn’t compete with what it terms distributed multi-region DMBSs. “There is no geographic distribution at scale,” scoffed PlanetScale CEO Sam Lambert, formerly the VP of engineering at GitHub, in an interview. “It’s snake oil!” For hyperscaling, a single region is mandatory, he said. And companies claiming to distribute across multiple regions don’t cut the mustard in his view: “You can’t lie to people about your database. It’s too important.”
So far, PlanetScale seems to have succeeded on takeoff. Prior to its general availability late last year, the DBMS was already in demand, officials say, and growth is robust. So is funding: In November 2021, the company scored $50 million in a Series C, bringing its total to $105 million since its founding four years ago. Investors include Kleiner Perkins, a16z, SignalFire, Insight Partners, Tom Preston Werner (co-founder and CEO of GitHub), Jack Altman (CEO and founder of Lattice), and Max Mellen (co-founder of Instacart).
PlanetScale’s competition spans the world of data lakes and warehouses, as well as distributed DBMSs (despite CEO Lambert's objections). Legacy transaction processing database suppliers such as IBM (NYSE: IBM) and Oracle (NYSE: ORCL) loom large. AWS and Google have their own solutions with Amazon RDS and Cloud SQL, respectively. Further, the clamor for hyperscaler transaction processing will likely widen the scope of competitors over time.
Still, PlanetScale’s track record is impressive. This is one to watch.
















